pSwapchains[0] images passed to present must be in layout VK_IMAGE_LAYOUT_PRESENT_SRC_KHR or VK_IMAGE_LAYOUT_SHARED_PRESENT_KHR but is in VK_IMAGE_LAYOUT_UNDEFINED. The Vulkan spec states: Each element of pImageIndices must be the index of a presentable image acquired from the swapchain specified by the corresponding element of the pSwapchains array, and the presented image subresource must be in the VK_IMAGE_LAYOUT_PRESENT_SRC_KHR layout at the time the operation is executed on a VkDevice (https://github.com/KhronosGroup/Vulkan-Docs/search?q=VUID-VkPresentInfoKHR-pImageIndices-01296)
This year is my first year doing the Advent of Code challenge, and today (2021 Day 7)'s challenge is a fun one.
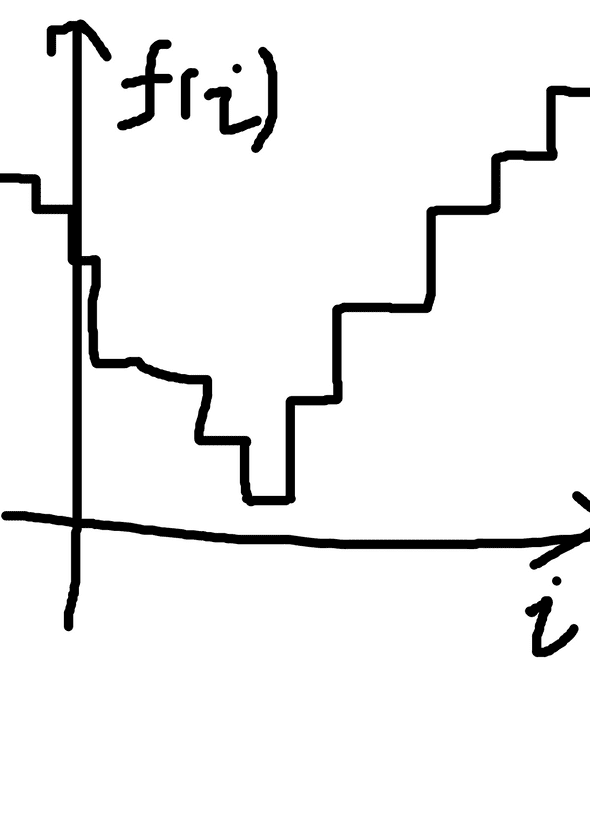
I won't go to the details, but the problem involves finding the minimum for a function. The function takes an integer and returns another integer. An interesting property of that function is that it has one "valley": Everything at the left of the global minimal point monotonically decreases. Everything at the right of the global minimal point monotonically increases.
You can think the function output as a bunch of integers like
100, 81, 56, 32, 16, 33, 44, 78, 129
And we want to find out the value 16.
Naively we can evaluate the function at every point in the domain and then find the minimum,
and a slightly better way is to evaluate the function until we find where the result starts to increase.
Both strategies requires O(n) time, but since our data are nicely "sorted," we can do better.
Ternary Search
Ternary Search, similar to binary search, expliots our data's pattern, and can achieve O(log n) asymptotic time.
Wikipedia describe it as a technique for "finding the minimum or maximum of a unimodal function," which is exactly the function we want to solve. The basic idea is simple: if we partition our domain into three segment by two point: left and right, then we can evaluate the function at left and right and get several cases:
f(left) < f(right)
f(left) > f(right)
f(left) == f(right)
If f(left) < f(right), which means either both left and right points are greater than the position of the local minimum, or left is less than the position of local minimum and right is greater than the position of local minimum. In either case, we know that the local minimum is not at the right hand side of right, so we can discard that part of the domain.
If f(left) > f(right), similarly we can discard the left hand side of left. And if f(left) == f(right), we can discard both side and only keep the range [left, right].
We can equally trisect the domain into left and right, and then we can run the above process recursively or iteratively to solve the problem. We still need a terminate condition: since our left and right can be stuck if right - left <= 2, we stop there and then fall back to linear search. And we can have the following pseudocode:
var left = domain.min
var right = domain.max
while (right - left) > 3 {
let left_third = left + (right - left) / 3
let right_third = right - (right - left) / 3
if f(left_third) < f(right_third) {
right = right_third
} else {
left = left_third
}
}
for i in left until right get the smallest f(i)
It is an elegent and fun algorithm, and I am suprised that today is the first time I hear about it.
And hopefully now you also understand how and when to use this algorithm.
Later, the new requirement of the course project requires us to add another field, what we called captainsQuertersHealth, to the class,
so we made the following change:
However, we had tons of unit tests that test against the old interface and they don't care about the captainsQuertersHealth field.
My partner suggested adding a default parameter.
Since the course project is in Java, which doesn't support default parameters by default, he recommends adding an overloaded constructor:
This constructor delegates to the previous constructor and always default captainsQuertersHealth to one.
It is certainly convenient.
However, adding this constructor means that the compiler will not be able to generate a compile-time error at places where we use this constructor,
and at those places, we do care about captainsQuertersHealth.
As a result, it would postpone a compiler catchable bug to runtime.
I convinced my teammate that it was a bad idea.
And our final solution was to add a helper in unit tests:
对于编程初学者来说,我推荐 Bjarne Stroustrup(C++之父)的《C++程序设计:原理与实践》第二版(Programming: Principles and Practice Using C++ 2nd edition)。
这本书有中文翻译,不过就像我之前说的,如果您有一点的英文阅读能力,我建议您阅读原版。
因为这本书很厚,所以您不一定能够坚持看完整本,但是无论您看了多少页你都能学到东西。
在这种情况下,我同样会推荐 Bjarne Stroustrup 的《C++程序设计:原理与实践》第二版。
你可以看书看得比纯粹初学者更快一些,不过使用该书来系统地查漏补缺依然很有好处。
如果您更喜欢视频教程,
可以从 Kate Gregory 的C++ Fundamentals Including C++17开始。
如果我是另一门语言的资深人士并想学习 C++,该怎么办?
如果您已经精通了某个其他的编程语言,并且想开始学习一些 C++,
您可以直接选择更加进阶的材料。
对于书来说,
我建议阅读 Bjarne Stroustrup 的《C++程序设计语言》第四版(The C++ Programming Language (4th Edition))。
这本书是我读过的最好的技术书籍之一。
不过这本书也同样相当得厚。如果您没有时间阅读该书并且想要有一个简短的 C++介绍,
您可以购买《A Tour of C++》第二版。
加入North Denver Metro C++ Meetup是我大学阶段做出的最好决定之一。如果您有时间的话,参加一些本地的 C++见面会是一个非常不错的选择。(因为新冠的原因,现在绝大多数见面会以及大会都在网上召开,这有利有弊,但一个很大的优势是您现在可以参加全球的见面会)您可以在meetup.com网站上搜索本地的见面会。
I read almost nothing for a few months after the lockdown, but I started to pick up reading more for the last couple of months.
"C++ Best Practices" by Jason Turner — Buying Jason's book is a no-brainer for me considering I started to watch his C++ Weekly in 2016, and he was one of the people who inspired me to delve into C++ at that time. I particularly enjoy the chapter "25. Avoid default In switch Statements," which is a great practice not often mentioned, and "47. Fuzzing and Mutating," which provide concrete instructions on setting up fuzzing and mutating test.
"Effective C: An Introduction to Professional C Programming" by Robert C. Seacord — I love this book, and will recommend all C people, not just beginners, to read it. It is really easy to make mistakes when writing C code or using C APIs, and this book tries to mitigate the problem and teach best practices for writing secure C code. Since most commonly recommended C books are decades old, Effective C is a rare book covering up-to-date C standards and practices. Robert certainly knows about both the standard and modern techniques very well.
"Elm in Action" by Richard Feldman — This book introduces the Elm programming language from scratch by building a simple frontend application incrementally through chapters. In each chapter, "your boss" gives you more requirements, and the book introduces language features to fulfill the requirements. Even though I used Elm to build a few games before, I still find this book enjoyable as there are many practical Jewels in this book on building production web applications. The sections about inter-oping with Javascript by custom elements (instead of ports) and handling routings for single-page applications are particularly enlighting for me.
"Automata and Computability" by Dexter C. Kozen is a textbook I used in my Theory of Computation class. It is more like a course note than a traditional textbook, where topics are split into "lessons." I enjoy the writing style of this book.
"Analysis I: Third Edition" by Terence Tao — this is the textbook used for our university' mathematical analysis course. It is a solid read, and the points are conveyed clearly. I also found that I am quite interested in the topic of analysis.
"How to Take Smart Notes" by Sönke Ahrens: This book is recommended in the talk on "org-mode for non-programmers" by Noorah Alhasan
in Emscs-SF meetup.
I am positively surprised by this book. My expectation of "self-help" books is full of platitudes with little insights. Yet this book was one of the most profound books I read this year. And I immediately put the slip-box method described in the book into practice on this same book and other things I learned. The downside of this book is that it does not spend enough time on "How to take smart note," as the title suggests, but instead repeats a lot on "why." Nevertheless, these characteristics are pretty common in this kind of book.
Reread:
"Ray Tracing in One Weekend" book series by Peter Shirley — I reread this series as I both covered it in the Graphics Programming Virtual Meetup and did the Ocamlpt coding project based on the book series. In my opinion, this book is a must-read for graphics people and is also worth rereading.
"Quaternions for Computer Graphics" by John Vince — I read it in 2016 when I understood almost nothing and wanted to make a video game, and I was lost at chapter 7. This time, I finally get enough insights into quaternions.
Today I stumble upon an article These Modern Programming Languages Will Make You Suffer
after Twitter outrage.
The post is absurd and indeed a suffer to read for me.
However, it also receives 1k+ medium claps at the time of writing, and I cannot stay silent.
In essence, this article tries to promote functional languages and list their advantages.
As an FP fanboy myself, I love content that encourages the usage of functional programming.
However, this article is so biased and full of factual errors, to the degree that it only shows the author's lack of understanding in both the languages they hate and the languages they try to promote. And I am not even surprised to find that the author was behind another notorious medium clickbait, Object-Oriented Programming - The Trillion Dollar Disaster.
I will not focus on this article's opinions.
Various Twitter shitposts sometimes have more extreme views than this article.
Also, it is hard to criticize objectively on buzzwords such as "bad" or "a mess."
Instead, let's focus on the misleading factual errors.
Though I am sure that there are still many more factual errors in the section I missed or in languages where I don't have experience.
Pure functions
Functions that do not mutate(change) any state are called pure
Pure functions are deterministic and have no side-effect.
"Do not mutate" is way not enough to make a function "pure."
Surprisingly, the author has a correct description of pure function later in the post,
and similar discrepancy also happened more than once,
which made me wonder whether a large chunk of the article is "borrowed" from elsewhere.
C++
C++ is the perfect punch bag for a lot of reasons,
but still, you shouldn't bash on a language if you have no understanding of it.
The developers have to worry about manually releasing and allocating memory.
Do you know what RAII is? And have you ever used C++ or Rust before? The same argument can go to the author's rant on the lack of GC in Rust.
has only rudimentary concurrency mechanisms
Let me reply with a tweet from Bryce Lelbach.
Almost everything in this article is patently wrong, like the claim that "[C++] only rudimentary concurrency mechanisms". C++ has a formally verified memory and execution model, which is the defacto industry standard, and a rich library of concurrency primitives. https://t.co/idtcg7gRCy
since the early versions of C# were a Microsoft implementation of Java
C# was an imitation of Java. But it was a new language and never intended as an implementation of Java.
In particular, C# claims to support functional programming. I must disagree... What functional features should a language have? At the very least, built-in support for immutable data structures, pattern matching, pipe operator for function composition, Algebraic Datatypes.
Those are all great features, but none of them are the essence of functional programming.
The first functional language, Lisp, supports none of those features.
By the way, C# does support pattern matching. 1
The author seems to acknowledge this fact earlier and forget later,
again made me wonder whether some part of the post is "borrowed" from elsewhere.
rudimentary concurrency support
C# is the language that makes the async/await paradigm popular.
In C#, all references are nullable.
Except that there are nullable-references support and references can be made not-null by default.
Python
Language family: C
What does "The C family languages" even mean?
Languages share a syntax resemble C?
And how does Python suddenly become a C-family language?
Python is an interpreted language
"Interpreted language" is a common buzzword in this field without a clear definition.
Instead of the language itself, a language implementation decides whether it is "interpreted" or "compiled."
Plus, there are a lot of middle-ground between an ahead-of-time compiler and a tree-walk interpreter,
and most language implementations these days are in the middle ground.
Python is also pretty slow to start up
A Python VM usually boots up in less than 100ms.
Rust
Rust also suffers from a lot of unfair ranting for its "low productivity" in this article, and to be honest all the criticism for Rust in this article looks like from a quick Google search.
The runtime performance of Rust programs is a little faster than Go.
You can't compare the runtime performance of programming languages without context like that.
There are a lot of performance design tradeoff,
and a language that runs faster in one circumstance is possible to run slower in another.
The first language on our list with a modern null alternative
While JavaScript developers can use libraries that help with immutability, TypeScript developers typically have to rely on the native array/object spread operators
Both immutable.js and Rambda, the Javascript libraries that the author mentioned, provide typescript type definitions, and they are not harder to use compared to using them in JS.
Functional languages
As a person who tries to promote functional languages,
the author should know better about those languages.
Unfortunately, the author seems to have more errors in those languages,
probably because they change from "opinionated rant mode" into actually talking about language features in this section.
Haskell
There's no type system more powerful than Haskell.
No type system can be considered the most "powerful."
By the way, what about dependent type languages 4?
OCaml
There're three package managers — Opam, Dune, and Esy.
Dune is not a package manager, but instead a build system. It is often used in combination with Opam.
The go-to book for learning OCaml is Real World OCaml. The book hasn't been updated since 2013, and many of the examples are outdated.
The 2nd edition of Real World OCaml is up-to-date and also available freely online.
Scala
Scala has first-class support for immutable data structures (using case classes).
The Scala standard library does provide fantastic support for immutable data structures.
However, case classes have nothing to do with those data structures.
Elm
The only time when you will encounter runtime errors with Elm is when interacting with outside JavaScript code.
Unfortunately, the Elm compiler still can generate Javascript code that throws exceptions at runtime.
interop with JavaScript libraries next to impossible
This means that the developers have no access to the vast ecosystem of libraries and components made for React.
You can make a React component a custom element.
We don’t even know whether or not he’s still working full-time on Elm. The language might actually be dead by now.
Evan is still doing work on Elm and interacts with the community regularly.
Reason ML
Just like TypeScript, ReasonML has access to the entire JavaScript ecosystem.
Using Javascript libraries in Reason requires some boilerplates (external), just like in Elm.
React initially was written in OCaml
The first prototype of React was written in Standard ML, rather than OCaml.
Elixir
Language family: ML.
Ok, I can stand that you say Haskell or Elm is in the ML family (though I disagree), but what is a dynamic-typed language doing here?
Conclusion
The article has some good content on pure functions, algebraic data types, pattern matching, and error-handling in FP languages.
If the author removes all the biased, incorrect, and misleading content, I would recommend it for people to read.
However, the author chooses a different path.
Unfortunately, the Internet always rewards clickbait and sensational articles these days instead of posts with meaningful content.
Also, what worries me is that these kinds of blog posts will push people away from functional languages.
A minority of trolls make people lose faith in the whole community.
For example, here is one comment on Medium to the article:
Ooh, you're a functional programmer! That explains why I had that feeling you didn't know what you were talking about.
I can stop reading now. I read enough flawed examples, dubious comparisons and more from articles written by your kind."
Rest assured that most people in the functional programming community are friendly and don't have that kind of bias against your favorite language.
Today I start to experiment with the WebGPU API, and I choose to use the wgpu-rs implementation in Rust.
I am happy with the experience overall, but one difficulty I met is the long iterative compilation time:
The compile-time of my webgpu project is ridiculously slow (about 10s for this single file), any #Rust expert know how to improve that? https://t.co/SVZYs54L7E
For some applications, slow compile-time is OK.
Coding some hard algorithms requires extensive thinking,
and if they compile and pass unit tests,
they are likely correct.
By contrast, for graphics and game programming, iteration time is paramount.
A lot of the time, there are no right or wrong answer to a problem,
instead, we need to do a lot of small tweakings.
What I need to do is to create a config file ~/.cargo/config as
[build]rustflags=["-C","link-arg=-fuse-ld=lld",]
This flag sets lld to the linker, which is way faster than Rust's default linker.
And I also need to install lld on my computer.
And this simple change magically makes my iterative compilation time under 3s.
It is still not ideal from my perspective, but at least I can enjoy doing this project again.
Explicit signature is required when using recursive modules,
as the compiler can no longer deduce the module signature with recursion.
A typical recursive module looks like the following:
modulerec M :sig(* explicit signature *)end=struct(* Implementations *)end
And we can even have mutually recursive modules, for example:
modulerec A :sig...end=struct...endand B :sig...end=struct...end
My primary use case of recursive modules is to combine with first-class modules.
First-class modules are ordinary values that wrap a module.
It is a powerful way to introduce dynamic polymorphism in OCaml.
Dynamic polymorphism is usually combined with recursive data types,
but Ocaml modules are not recursive by default.
Thus, recursive modules serve as valuable additions.
For example,
I use first-class modules and recursive modules in my ocamlpt project.
Ocamlpt is a path tracer,
where its scene contains different kinds of shapes.
The signature of a shape is the following:
moduletypeShape=sigtype t
val hit:Ray.t -> t ->Material.hit_record option
val bounding_box: t ->Aabb.t
end
We want to make the shape polymorphic, so we need to use first-class modules.
In the below code, I introduce a Shape_instance modules that wrap both the shape module and the value of that module,
and I also add a build_shape function that builds first-class modules of the signature of Shape_instance.
This way, we can store those first-class modules, and Whenever we want to use them, we can unwrap the first-class modules to get a concrete Shape_instance module.
moduletypeShape_instance=sigmodule S:Shapeval this: S.t
endlet build_shape
(type a)(module S :Shapewithtype t = a)(shape: a)=(modulestructmodule S = S
let this = shape
end:Shape_instance)
The above code is good enough to deal with concrete shapes such as spheres or triangles.
However, the shapes are organized in a tree structure called
bounding volume hierarchy (BVH).
And each BVH node can contain other shapes, including BVH nodes themselves.
We can implement the BVH node with recursive modules:
modulerecBvh_node:sigincludeShapeval create:(moduleShape_instance) list -> t
end=structtype t ={
left:(moduleShape_instance);
right:(moduleShape_instance);
aabb:Aabb.t;}(* Other members of the Bvh_node module *)(* Creating bvh code from a list of objects *)letrec create (shapes:(moduleShape_instance) list)=...(* if shapes contain 3 elements *)let left =...and right =...inlet aabb =Aabb.union left.aabb right.aabb in{ left=(build_shape (moduleBvh_node) left);
right=(build_shape (moduleBvh_node) right);
aabb }end
The above code works like magic,
but the code would not compile without the rec keyword before Bvh_node,
since the create function refers to the module Bvh_node itself.
All in all,
recursive modules is a way to support cyclic dependencies among components
that the purely hierarchical module systems cannot support.
Such cyclic dependencies are usually undesirable and can be avoided by changing the software design.
Nevertheless, sometimes there are legitimate reasons to have a module depend on itself,
especially consider how versatile the OCaml module system is.
In those cases, recursive modules can serve as a valuable asset.
Recently, I have seen some people passing complex mutable lambdas to standard algorithms.
Those usages usually come from one mindset:
"Since we want to follow 'no raw-loop,'
and the choice of STL algorithms is limited,
what can we do other than using a mutable lambda to hold our complicated logic?"
I think that both premises of this thought are wrong.
First, "no raw-loop" should be treated as an ideal instead of dogma.
Second, even though STL algorithms cannot cover every use case,
we can always write algorithms to fit our needs.
I expressed this thoughts in the following tweet:
Random thought: if you want to pass a complicated mutable lambda to a C++ standard algorithm, you are using the wrong algorithm.
And this post tries to expend this thought a little bit.
Mutable Lambdas destroy the beauty of <algorithms>
Why we use <algorithm>? Is it because it is "elegant" or "modern?"
Or is it because "Some experts said so?"
Both are horrible reasons to prefer <algorithm> over loops.
For me,
<algorithm> provides the following benefits:
Less mutable states
Declarative
Express intent
Known correct implementation
Mutable lambda destroys all of them.
First, STL algorithms encapsulate mutable states into small functions.
Nevertheless, we only need mutable lambda when our algorithm fails to encapsulate all mutable logics.
Second,
since the mutable states and complex control flow are back,
we can no longer call our implementation declarative.
Third,
since we need complicated logic inside a lambda to stretch the algorithm to perform our task,
the algorithm does not express our intent.
Fourth,
since the algorithm does not express our intent,
even though the algorithm itself is correct,
there can still be bugs lure in our own hard-to-understand code.
A LeetCode example
Let's look at the following C++ solution to the LeetCode Two Sum problem by Yacob Cohen-Arazi. The problem is worded as follows: "Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target." and LeetCode provides the type signature of the twoSum function that we cannot change.
This version is long, messy, and hard to read.
It also contains five mutable states m, idx1, idx2, i, and target,
even though target is never modified.
Here is the loop version I wrote that are doing essentially the same logic:
std::vector<int>twoSum(std::vector<int>& nums,int target){
std::unordered_map<int,int> nums_map;constint size =static_cast<int>(nums.size());for(int i =0; i < size;++i){constauto item = nums[i];constauto iter = nums_map.find(target - item);if(iter != nums_map.end()){return{iter->second, i};}
nums_map.emplace(item, i);}throw std::runtime_error{"No solution exist"};}
This loop version is shorter, easier to understand, and only contains two mutable states: the map nums_map and index i.
The <algorithm> version lands badly here because std::find_if does not match this problem's intent.
std::find_if finds a single element that matches a predicator,
but our situation requires to find two elements that match a predicator together.
As a result,
it does not provide enough useful functionalities for this problem
but instead serves as an obstacle.
I consider this kind of <algorithm> usages instances of the abstraction inversion anti-pattern,
where the abstraction is so unfit for the task that we start to re-implements the implementation details that our abstractions suppose to hideaway.
This kind of usage makes the code hard to read,
introduces potential non-trivial runtime cost,
and increases the possibility of introducing bugs.
The <algorithm> header tries to address all of the adversities,
but by using mutable lambda,
we somehow land us in a situation worse than the loop counterparts of our functions.
Another Example: Calculates inner product until it satisfies a predicate
Ok, which algorithm should I use to calculate the inner product until it exceeds a value and get the index when it happened? Didn't find find just the right thing in a table by @code_report that doesn't require a mutable lambda.
This problem is tricky to solve with STL algorithms
since STL algorithms are designed to compose sequentially,
and as we will see in the loop version,
there is multiple interleaved logic during the iteration.
Thus, I will use the loop version as the starting point.
Since Dima does not specify what happens if we didn't find the index,
I return the final result of i,
which should be the index of the last element plus one:
template<std::input_iterator Itr, std::input_iterator Itr2,classT>autoinner_product_till(
Itr first1, Itr last1, Itr2 first2,const T upper_bound)-> std::size_t
{
T acc{};
std::size_t i =0;for(; first1 != last1;++first1,++first2,++i){
acc = std::move(acc)+*first1 **first2;if(acc > upper_bound){return i;}}return i;}
This version is certainly not ideal.
It contains four mutable states first1, first2, i, and acc.
Nevertheless,
the logic inside the loop is simple,
and every decent C++ programmers should be able to grasp this code
in a relatively short amount of time.
I am satisfied with this version.
Even the person who proposed "no raw loop" ideology in the first place,
Sean parent,
will not consider this kind of simple loops that are nicely encapsulated in a function "raw loops."
A raw loop is any loop inside a function where the function serves purpose larger than the algorithm implemented by the loop — Sean Parent, 2013 1
The std::find + mutable lambda version, however,
is certainly inferior to the loop version.
This version contains the same amount of mutable states,
and is signaficantly harder to read even for people familiar
with this kind of lambda-heavy style of programming:
If we step back a little bit and think about what logic we try to achieve here.
We can find two interleaving steps.
First, we need to perform an inner product to the elements we meet so far.
Second, we find whether this calculated inner product is greater than the upper_bound.
If we ignore the "interleaving" part,
then we can use std::transform and std::partial_sum to perform the first step and std::find_if to perform the second step:
This version is the closest to my thought flow,
however, it is also very inefficient
since it allocates extra heap memory and eagerly computes results that we may not need.
Lazy ranges view solves the performance problem,
If ranges have numeric algorithms support,
then we can potentially write the following code:
template<std::input_range Range,classT>autoinner_product_till(Range r1, Range r2,const T upper_bound)-> std::size_t
{return std::ranges::distance(
std::view::transform(r1, r2, std::multiplies<T>{})| std::view::partial_sum
| std::view::take_while([&](T e){return e > upper_bound;})););}
This version is splendid.
It does not allocate and exit early,
so in theory, it can be as efficient as the raw loop version or the mutable lambda version,
and it is certainly much more readable and less error-prone to write than both of them.
Unfortunately, none of the algorithms in the <numeric> header is included in the C++20 ranges.
As a result, std::view::partial_sum is not a thing at the time of this writing.
Nevertheless, the range-v3 library includes all those functionalities.
Don't be afraid of writing your own algorithm
Another way to solve this problem is to write your own algorithm.
For example, in the above example,
we can write our own view::partial_sum view adapter.
Our algorithm often does not need to be very generic in practice,
as you can always enhance it later when you need to reuse this piece of code.
The starting point of an algorithm can merely be "extracting a loop into a function."2
Also, the interesting thing is that
the above inner_product_till is an STL-compatible algorithm.
And we can treat it as one of the lowest levels of abstraction.
If it is well tested, fast, and well behaved, who cares about whether it uses loops or other algorithms under-the-hood?
It is not as generic as std::inner_product,
but we can always add initial value and the plus/multiply binary operations as parameters later if we need them.
What about using mutable lambdas in std::generate?
A lot of usages of std::generate use mutable lambdas as a "generator" function.
For example, the following code generates the first 20 numbers of
the recurrence relationship x0=0,xn=2xn−1+1.
int seq[20];
std::generate(std::begin(seq), std::end(seq),[x =0]()mutable{return std::exchange(x, x *2+1);});
This kind of "generator" usage of std::generate and mutable lambdas is common,
and I think, unlike previous examples, they are fine.
There is an advantage of this version compared to using a loop.
Compared to the equivalent loop version,
the scope of the mutable variable x is constrained to be in lambda's scope.
And we should strive to make the scope of variables (especially mutable) as small as possible.
Nevertheless, we can surround the loop with explicit brace pair to get a similar effect:
int seq[20];{int x =1;for(auto& elem: seq){
elem = std::exchange(x, x *2+1);}}
Consider the alternatives over passing mutable lambdas to STL algorithms
To sum everything up, I believe passing mutable lambdas to STL algorithms other than std::generate or std::generate_n is an anti-pattern that we should try to avoid. There are several alternatives. Sometimes we can switch to a better algorithm. Sometimes using a plain-old loop is the better option. And sometimes, we can write our customized algorithms to achieve the task.
std::vector<ImmutablePoint&> triangles1;// Error
std::vector<std::reference_wrapper<ImmutablePoint>> triangles2;// Ok
std::vector<ImmutablePoint*> triangles3;// Ok
It is easy to make mistakes when conducting mathematical proofs.
Nevertheless, you can find some recurring error patterns in those proofs.
And some of the most common reasons are related to the innocuous-looking number zero.
Division-by-zero fun
Let's look at the following "proof" of 1=2:
let a,b∈Z such that a=ba2a2−b2(a+b)(a−b)a+ba+a2a2=ab=ab−b2=b(a−b)=b=a=a=1
What is wrong here?
We cancel both side of the equation by a−b, but our premise includes a=b,
so we have a division-by-zero problem.
Generally, performing cancellation without a zero-check is a terrible idea and should be avoided.
Sets with zero elements
Ok, here is another stupid "proof" of that "all objects are the same." We will assume that objects are countable.
Proof:
Let S be the set of all objects.
And let the property P(n) mean that all subsets of S of size at most n contain the same same objects.
Formally:
P(n)≡∀X∈Pow(S),∣X∣≤n such that ∀o,o′∈X,o=o′
where Pow(S) is the power set of the set S, which is defined by all subsets of S, and ∣X∣ means the cardinality (elements count) of X.
We want to prove that ∀n>1,P(n). And we will prove that by mathematical induction on n.
Base case (n=1):
This is trivial as the singleton set of object can only contain the same object.
Inductive cases:
We treat P(n) as our inductive hypothesis, and we need to prove P(n+1).
Without the loss of generality,
pick an arbitrary set X∈Pow(S) such that ∣X∣=n+1.
Pick two objects x,x′∈X, and let's show x=x′.
Let Y=X−x and Y′=X−x′.
Since ∣Y∣≤n,∣Y′∣≤n, we know that P(Y) and P(Y′) by the inductive hypothesis.
Pick an arbitrary object y∈Y∪Y′.
We get y=x because of P(Y) and x,y∈Y.
Similarly, y=x′.
Thus, x=x′,
which proves the inductive steps and the "theorem" ∀n>1,P(n).
Again the mistake here is related to zero.
∣Y∪Y′∣ can well be zero, so we cannot just "pick" an element from it.
If you are from a more programming background,
it is no coincidence that dividing by zero or getting an element from a collection of zero-elements will cause horrible run-time errors.
I hope you have fun reading this post, just as me having fun writing it.
"Real World OCaml Functional programming for the masses 2nd edition" by Yaron Minsky, Anil Madhavapeddy, and Jason Hickey -
I highly recommend this book for people who want to learn Ocaml in-depth.
However, it does require familiarity with functional programming to understand. I
understand a lot of advanced ML language features such as Functors (witch very different from Haskell functors) and First-Class Modules by reading this book.
Also, as the name suggests, this book is a "real world" programming book that spends enough time on the build system and libraries.
"The Formal Semantics of Programming Languages: An Introduction" by Glynn Winskel -
The book has a clear explanation of the programming language concepts.
It is centralized around a little programming language IMP, and the book defines it with different style semantics.
On the other side, since this book is so dated (1993), the notations used in the book are quite weird.
"Practical Foundations for Programming Languages" by Robert Harper -
Maybe I am dumb, but I find this book a dry and tough read.
A lot of the time, this book read more like a reference menu than a textbook.
If you don't understand the concepts, reading this book is probably not an efficient way to help you.
On the other hand, if you do understand the concepts, then you will find the definition mechanical.
Simultaneously reading the Winskel book helps a lot in understanding this book.
I like the emphasis on language static of this book, which is a missing part of the Winskel book.
"Hands-On Design Patterns with C++" by Fedor G. Pikus -
I start reading this one after someone recommended it on the cpplang slack channel.
I like how this book focuses on idiomatic C++ instead of design patterns.
My only gripe about this book is that some examples are quite contrived or may not use the right pattern to solve the problems.
For example, the game example in the template method chapter should be implemented with a component architecture or ECS instead of inheritance.
I understand that those examples are just for demonstration purposes, but they can be misleading for people who don't know the alternatives.
"The Elements of Style" by William Strunk Jr. and E. B. White - A cute little book on how to write English efficiently.
I have to say, nevertheless, that understanding the points from the book is far from applying them as an instinct.
$ip2state$int f(void) DB 02H
DB 08H
DB 00H$cppxdata$int f(void) DB 060H
DD imagerel $ip2state$int f(void)
int f(void) PROC ; f, COMDAT$LN5:
sub rsp, 40; 00000028H
call int g(void) ; g
npad 1
add rsp, 40; 00000028H
ret 0
int f(void) ENDP ; f
gcc
f():
sub rsp, 8
call g()
add rsp, 8
ret
clang
f():
push rax
call g()
pop rcx
ret
mov rdi, rax
call __clang_call_terminate
__clang_call_terminate:
push rax
call __cxa_begin_catch
call std::terminate()