(全文约 4 万字,主要内容来自 2023 年 12 月 21 日在中科大校友会 AI 沙龙上的 2 小时报告,也是 2024 年 1 月 6 日知乎 AI 先行者沙龙 15 分钟报告内容的技术扩展版本,文章经笔者整理和扩展)

非常荣幸来到科大校友会 AI 沙龙分享一些我对 AI Agent 的思考。我是 1000(2010 级理科实验班)的李博杰,2014-2019 年在中科大和微软亚洲研究院读联合培养博士,2019-2023 年是华为首届天才少年,如今我跟一批科大校友一起在做 AI Agent 领域的创业。
今天是汤晓鸥教授的头七,因此我特别把今天的 PPT 调成了黑色背景,这也是我第一次用黑色背景的 PPT 做报告。我也希望随着 AI 技术的发展,未来每个人都可以有自己的数字分身,实现灵魂在数字世界中的永生,在这个世界里生命不再有限,也就不再有分离的悲伤。
AI:有趣和有用
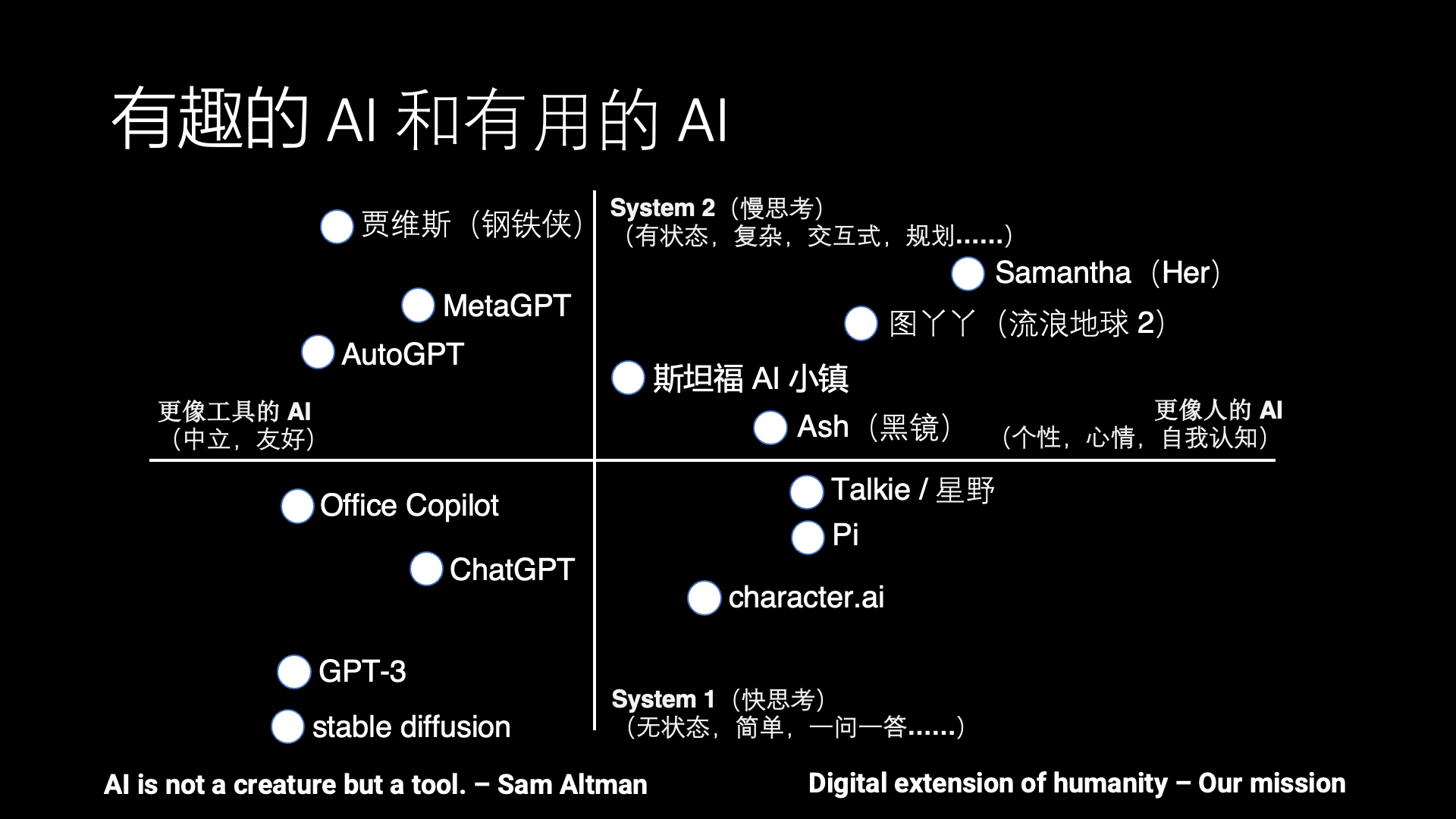
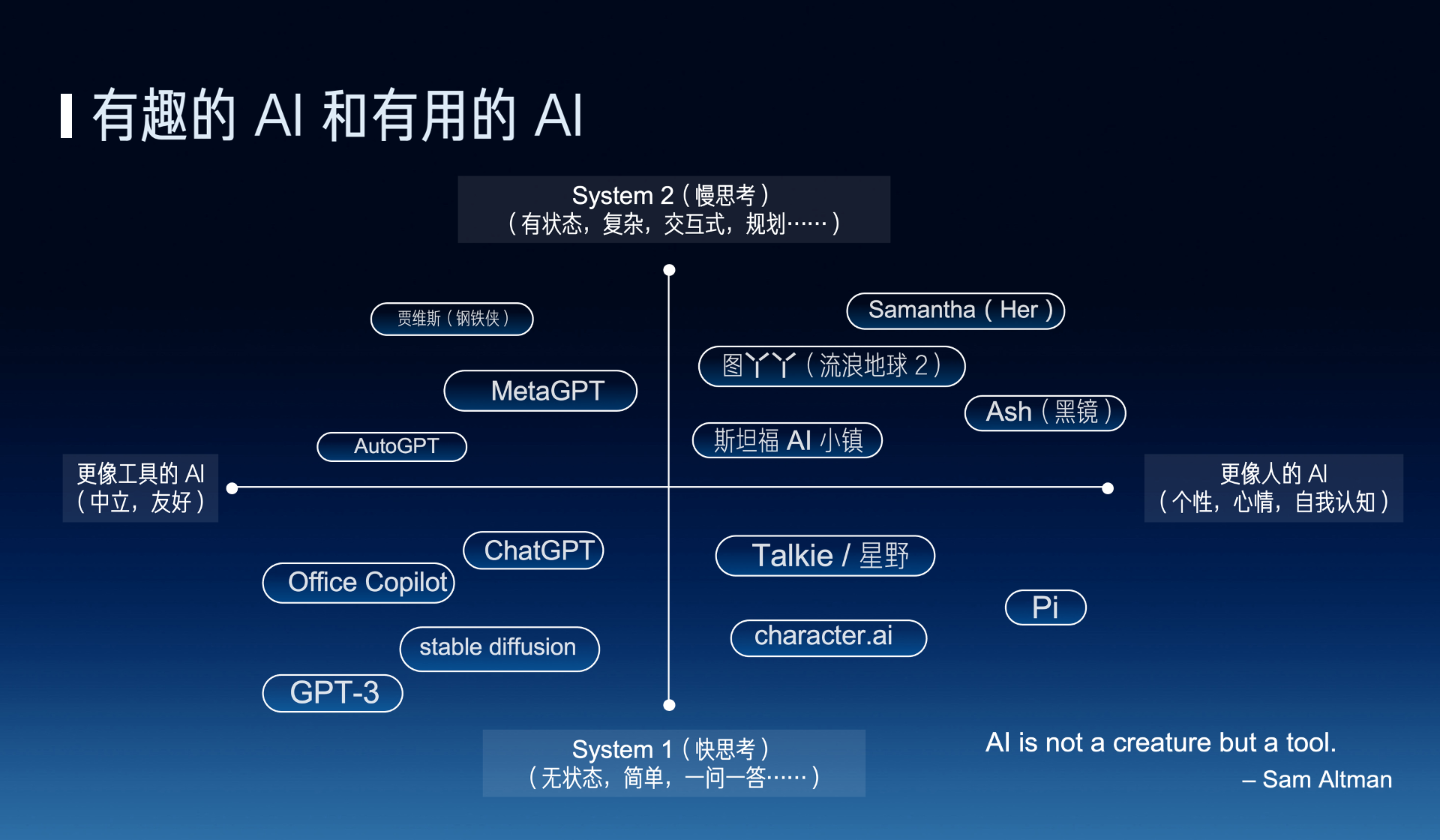
AI 的发展目前一直有两个方向,一个是有趣的 AI,也就是更像人的 AI,另外一个方向就是更有用的 AI,也就是更像工具的 AI。
AI 应该更像人还是更像工具呢?其实是有很多争议的。比如说 OpenAI 的 CEO Sam Altman 就说,AI 应该是一个工具,它不应该是一个生命。而很多科幻电影里的 AI 其实更像人,比如说 Her 里面的 Samantha,还有《流浪地球 2》里面的图丫丫,黑镜里面的 Ash,所以我们希望能把这些科幻中的场景带到现实。只有少数科幻电影里面的 AI 是工具向的,比如《钢铁侠》里面的贾维斯。
除了有趣和有用这个水平方向的之外,还有另外一个上下的维度,就是快思考和慢思考。这是一个神经科学的概念,出自一本书《思考,快与慢》,它里面就说人的思考可以分为快思考和慢思考。
所谓的快思考就是不需要过脑子的基础视觉、听觉等感知能力和说话等表达能力,像 ChatGPT、stable diffusion 这种一问一答、解决特定问题的 AI 可以认为是一种工具向的快思考,你不问它问题的时候,它不会主动去找你。而 Character AI、Inflection Pi 和 Talkie(星野)这些 AI Agent 产品都是模拟一个人或者动漫游戏角色的对话,但这些对话不涉及复杂任务的解决,也没有长期记忆,因此只能用来闲聊,没法像 Her 里面的 Samantha 那样帮忙解决生活和工作中的问题。
而慢思考就是有状态的复杂思考,也就是说如何去规划和解决一个复杂的问题,先做什么、后做什么。比如 MetaGPT 写代码是模拟一个软件开发团队的分工合作,AutoGPT 是把一个复杂任务拆分成很多个阶段来一步步完成,虽然这些系统在实用中还有很多问题,但已经是一个具备慢思考能力的雏形了。
遗憾的是,现有产品中几乎没有在第一象限,兼具慢思考和类人属性的 AI Agent。斯坦福 AI 小镇是个不错的学术界尝试,但斯坦福 AI 小镇里面没有真人的交互,而且 AI Agent 一天的作息时间表都是事先排好的,因此并不是很有趣。
有趣的是,科幻电影里面的 AI 其实大部分是在这个第一象限。因此这就是目前 AI Agent 和人类梦想之间的差距。因此我们在做的事情跟 Sam Altman 说的正好相反,我们希望让 AI 更像人,同时又具备慢思考的能力,最终演进成一个数字生命。